By Tony Ward, Director, StatCore
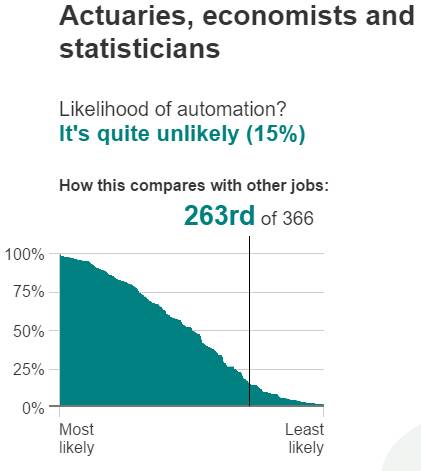
That makes sense. The role of an actuary requires creative thinking, problem formulation, communication skills, judgement, a moral code and domain knowledge. All which are hard to automate. Don’t get too comfortable though….
Will a data scientist take my job in the next two decades?
Almost certainly – and probably much sooner than expected in areas where predictive modelling is the dominant skill e.g. personal lines pricing and marketing. The shift towards data science has been recognised in the US with the Casualty Actuarial Society (CAS) introducing a speciality credential in data science. The transition is also underway in the UK with several insurers starting up specialist “data science” teams. Machine learning – a trademark skill of a data scientist will soon become the preferred method of building predictive models. Point and click Generalised Linear Modelling (GLM) – the current industry standard – will become the “old way of doing things”.
Hang on, aren’t actuaries the data scientists of the insurance world?
In 2012 the Harvard Business Review declared the Data Scientist role as “The sexiest job of the 21st Century”. Since then the job market for these professionals has gone through the roof, as businesses clamour to hire these rare “Unicorns” that promise to turn their big data into big profits.
It is therefore no surprise that many professionals have chosen to rebrand themselves as Data Scientists. So what is a data scientist? At times it feels there are more people writing about data science than actually doing data science, so I won’t go too deeply into definitions and semantics here. My personal view is that calling yourself a Data Scientist is a statement and to back up that statement requires expertise in the following areas.
Unstructured data – the ability to handle unstructured data such as text, images, audio and even video data is the hallmark of a data scientist. There are companies out there that will match your customer base to a social media account and provide a real time stream of tweets and Facebook posts. Do you feel confident working with this this type of unstructured data? Could you test its predictive power in your risk pricing models?
Machine learning – Machine learning represents a cultural shift in the way predictive models are built. Statistical modelling is the traditional approach to building predictive models and requires the user to decide on a final model having performed some form of test on each variable. This is a manual process and therefore does not scale to wide datasets with many predictors. In machine learning the decision to include/exclude a variable is taken care of automatically, which allows us to simultaneously consider thousands of predictors.
Cloud Computing - Cloud computing enables on-demand access to very powerful machines, which is especially useful when doing machine learning. Understanding just what size of kit you need and how to make the most of it is a skill in itself. Having access to a machine with several cores allows you to run tasks in parallel rather than sequentially leading to faster run times. K-fold cross validation and the Random Forest algorithm are examples of embarrassingly parallel tasks which can be speeded up by using multiple cores. Simply put, unless your Organisation decides to move to the cloud or invests heavily in expensive kit you should get used to looking at that egg timer!
Algorithmic Pricing
In October 2014, I took a three months’ career break to study Machine Learning at Stanford University. With a Master’s Degree in Statistics I already had a decent understanding of traditional linear modelling techniques, but I wanted to see what the next generation of predictive modelling techniques was all about. Ultimately I wanted to develop a framework for building pricing models that was more accurate and quicker to build than the current industry standard whilst still being easy to explain and implement on production systems.
I quickly discovered it was pretty easy to beat a GLM model in terms of accuracy by using either a Gradient Boosted Machine (GBM) or a Deep Learning Network. These methods sacrifice interpretability for an improvement in predictive performance, which in some situations is a good trade-off. For example no one really cares why a spam filter works, so long as it works. More importantly these methods lack a quick route to market for insurance companies, since putting them into production is not a straightforward task.
Penalised Regression on the other hand retains the model form of a traditional GLM but uses regularisation to select which variables appear in the model automatically. Penalised Regression on its own is not enough to replace traditional GLM, as we still need to handle non- linear relationships and interactions intelligently. Our proprietary new framework “Algorithmic Pricing” does exactly that by supplementing Penalised Regression with 3 other learning algorithms. Which ones did I use? Well I can’t give away all my secrets!
To read more about Algorithmic Pricing go here |